Survey Statistics using BRFSS data
What is a survey?
A systematic method for gathering information from a sample of entities for the purposes of constructing quantitative descriptors of the attributes of the larger population of which the entities are members
Questions when identifying a survey data source:
- What is the target population?
- What is the sampling frame
- how do we know who could be included?
- What is the sample design?
- What is the mode of data collection?
- Is the survey ongoing or a one-time collection?
Core Concepts
Sampling units - where information will be collected from Sampling frame - the set of sampling units containing distinct sets of population members
Weights and weighting
Surveys with complex sample designs will often have:
- Unequal probabilities of selection
- Variation in response rates across groups
- Differences in distributions of characteristics compared to the population
Weights are used to compensate for these features
What is a weight?
A weight is used to indicate the relative strength of an observation.
In the simplest case, each observation is counted equally.
For example, if we have five observations, and wish to calculate the mean, we just add up the values and divide by 5.
Dataset with 5 cases
| y | weight | |
|---|---|---|
| 1 | 4 | 1 |
| 2 | 2 | 2 |
| 3 | 1 | 4 |
| 4 | 5 | 1 |
| 5 | 2 | 2 |
Unweighted sample mean
## [1] 2.8Weighted sample mean
## [1] 2.1Difference between unweighted and weighted data
With unweighted data, each case is counted equally.
Unweighted data represent only those in the sample who provide data.
With weighted data, each case is counted relative to its representation in the population.
Weights allow analyses that represent the target population.
Weights compensate for collecting data from a sample rather than the entire population and for using a complex sample design.
Weights adjust for differential selection probabilities and reduce bias associated with non-response by adjusting for differential nonresponse. Weights are used when estimating characteristics of the population.
Sample variance estimation in complex designs
Standard errors are produced for estimates from sample surveys. They are a measure of the variance in the estimates associated with the selected sample being one of many possible samples.
Standard errors are used to test hypotheses and to study group differences.
Using inaccurate standard errors can lead to identification of statistically significant results where none are present and vice versa
Complex survey designs and standard errors
The usual standard error formula assumes a simple random sample.
Software packages designed for simple random samples tend to underestimate the standard errors for complex sample designs.
Standard errors for estimates from a complex sample must account for the within cluster/ across cluster variation.
Special software can make the adjustment, or this adjustment can be approximated using the design effect.
Methods for sample variance estimation
There are basically 3 ways in which software estimates variances: 1) Naive method 2) Taylor series approximation 3) Balanced or Jackknife replication
Data Example
This example will cover the use of R functions for analyzing complex survey data. Most social and health surveys are not simple random samples of the population, but instead consist of respondents from a complex survey design.
These designs often stratify the population based on one or more characteristics, including geography, race, age, etc. In addition the designs can be multi-stage, meaning that initial strata are created, then respondents are sampled from smaller units within those strata.
An example would be if a school district was chosen as a sample strata, and then schools were then chosen as the primary sampling units (PSUs) within the district. From this 2 stage design, we could further sample classrooms within the school (3 stage design) or simply sample students (or whatever our unit of interest is).
Multi-stage sampling
- Non-random sampling
- Population consists of known sub-groups called clusters
- A 2 -stage sample might be households within neighborhoods, or children within schools
- We may choose a random sample of schools/neighborhoods at the first stage, and a random sample of people within each school/neighborhood as the second stage
- We need to be careful because the observations in the second stage are not independent of one another
- Increased probability of selection for children in a selected school
- This type of sampling leads to dependent observations
Here’s a picture of this:

Multistage Sampling - From Kawachi and Berkman, 2003
A second feature of survey data we often want to account for is differential respondent weighting. This means that each respondent is given a weight to represent how common that particular respondent is within the population. This reflects the differenital probability of sampling based on respondent characteristics.
As demographers, we are also often interested in making inference for the population, not just the sample, so our results must be generalizable to the population at large. Sample weights are used in the process as well.
When such data are analyzed, we must take into account this nesting structure (sample design) as well as the respondent sample weight in order to make valid estimates of ANY statistical parameter. If we do not account for design, the parameter standard errors will be incorrect, and if we do not account for weighting, the parameters themselves will be incorrect and biased.
In general there are typically three things we need to find in our survey data codebooks: The sample strata identifier, the sample primary sampling unit identifier (often called a cluster identifier) and the respondent survey weight. These will typically have one of these names and should be easily identifiable in the codebook.
Statistical software will have special routines for analyzing these types of data and you must be aware that the diversity of statistical routines that generally exists will be lower for analyzing complex survey data, and some forms of analysis may not be available!
See Thomas Lumley’s Book on this!
Below I illustrate the use of survey characteristics when conducting descriptive analysis of a survey data set and a linear regression model estimated from that data. For this example I am using 2016 CDC Behavioral Risk Factor Surveillance System (BRFSS) SMART metro area survey data. Link
## Loading required package: carData##
## Please cite as:## Hlavac, Marek (2018). stargazer: Well-Formatted Regression and Summary Statistics Tables.## R package version 5.2.2. https://CRAN.R-project.org/package=stargazer## Loading required package: grid## Loading required package: Matrix## Loading required package: survival##
## Attaching package: 'survey'## The following object is masked from 'package:graphics':
##
## dotchart##
## Attaching package: 'dplyr'## The following object is masked from 'package:car':
##
## recode## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionRecoding of variables
Be sure to always check your codebooks!
#The names in the data are very ugly, so I make them less ugly
nams<-names(brfss_17)
head(nams, n=10)## [1] "dispcode" "statere1" "safetime" "hhadult" "genhlth" "physhlth"
## [7] "menthlth" "poorhlth" "hlthpln1" "persdoc2"#we see some names are lower case, some are upper and some have a little _ in the first position. This is a nightmare.
newnames<-tolower(gsub(pattern = "_",replacement = "",x = nams))
names(brfss_17)<-newnames
#Poor or fair self rated health
brfss_17$badhealth<-Recode(brfss_17$genhlth, recodes="4:5=1; 1:3=0; else=NA")
#sex
brfss_17$male<-as.factor(ifelse(brfss_17$sex==1, "Male", "Female"))
#race/ethnicity
brfss_17$black<-Recode(brfss_17$racegr3, recodes="2=1; 9=NA; else=0")
brfss_17$white<-Recode(brfss_17$racegr3, recodes="1=1; 9=NA; else=0")
brfss_17$other<-Recode(brfss_17$racegr3, recodes="3:4=1; 9=NA; else=0")
brfss_17$hispanic<-Recode(brfss_17$racegr3, recodes="5=1; 9=NA; else=0")
#insurance
brfss_17$ins<-Recode(brfss_17$hlthpln1, recodes ="7:9=NA; 1=1;2=0")
#income grouping
brfss_17$inc<-ifelse(brfss_17$incomg==9, NA, brfss_17$incomg)
#education level
brfss_17$educ<-Recode(brfss_17$educa, recodes="1:2='0Prim'; 3='1somehs'; 4='2hsgrad'; 5='3somecol'; 6='4colgrad';9=NA", as.factor=T)
brfss_17$educ<-relevel(brfss_17$educ, ref='2hsgrad')
#employment
brfss_17$employ<-Recode(brfss_17$employ1, recodes="1:2='Employed'; 2:6='nilf'; 7='retired'; 8='unable'; else=NA", as.factor=T)
brfss_17$employ<-relevel(brfss_17$employ, ref='Employed')
#marital status
brfss_17$marst<-Recode(brfss_17$marital, recodes="1='married'; 2='divorced'; 3='widowed'; 4='separated'; 5='nm';6='cohab'; else=NA", as.factor=T)
brfss_17$marst<-relevel(brfss_17$marst, ref='married')
#Age cut into intervals
brfss_17$agec<-cut(brfss_17$age80, breaks=c(0,24,39,59,79,99))
#BMI, in the brfss_17a the bmi variable has 2 implied decimal places, so we must divide by 100 to get real bmi's
brfss_17$bmi<-brfss_17$bmi5/100
brfss_17$obese<-ifelse(brfss_17$bmi>=30, 1, 0)Analysis
First, we will do some descriptive analysis, such as means and cross tabulations.
##
## 2hsgrad 0Prim 1somehs 3somecol 4colgrad
## 0 42226 2660 5583 50627 87690
## 1 13542 2413 3846 11555 9181##
## 2hsgrad 0Prim 1somehs 3somecol 4colgrad
## 0 0.75717257 0.52434457 0.59210945 0.81417452 0.90522447
## 1 0.24282743 0.47565543 0.40789055 0.18582548 0.09477553##
## Pearson's Chi-squared test
##
## data: table(brfss_17$badhealth, brfss_17$educ)
## X-squared = 12758, df = 4, p-value < 2.2e-16So basically all of these numbers are incorrect, since they all assume random sampling. Now, we must tell R what the survey design is and what the weight variable is, then we can re-do these so they are correct.
Create a survey design object
Now we identify the survey design. ids = PSU identifers, strata=strata identifiers, weights=case weights, data= the data frame where these variables are located. Lastly, I only include respondents with NON-MISSING case weights.
I first try to get only cities in the state of Texas by looking for “TX” in the MSA’s name field in the data.
Now I make the survey design object. You may be required to specify two options here:
survey.lonely.psuThis means that some of the strata only have 1 PSU within them. This does not allow for within strata variance to be calculated. So we often have to tell the computer to do something here. Two valid options are “adjust”, to center the stratum at the population mean rather than the stratum mean, and “average” to replace the variance contribution of the stratum by the average variance contribution across strata. (from ?surveyoptions)Nesting of PSU within strata. By default, PSUs have numeric identifiers that can overlap between strata. By specifying
nest=T, we tell R to relable the PSUs so they are unique across strata. If your survey requires this, it will throw a warning message.
brfss_17<-brfss_17%>%
filter(tx==1, is.na(mmsawt)==F)
#
options(survey.lonely.psu = "adjust")
des<-svydesign(ids=~1, strata=~ststr, weights=~mmsawt, data = brfss_17 )###simple weighted analysis Now , we re-do the analysis from above using only weights:
cat<-wtd.table(brfss_17$badhealth, brfss_17$educ, weights = brfss_17$mmsawt)
prop.table(wtd.table(brfss_17$badhealth, brfss_17$educ, weights = brfss_17$mmsawt), margin=2)## 2hsgrad 0Prim 1somehs 3somecol 4colgrad
## 0 0.75772036 0.60034582 0.65504645 0.83488335 0.91152544
## 1 0.24227964 0.39965418 0.34495355 0.16511665 0.08847456##
## 2hsgrad 0Prim 1somehs 3somecol 4colgrad
## 0 0.7089670 0.5686813 0.6220807 0.7798289 0.8838313
## 1 0.2910330 0.4313187 0.3779193 0.2201711 0.1161687There are differences, notably that the prevalence of poor SRH is higher in the sample than the population. This is important!
Let’s say we also want the standard errors of these percentages. This can be found for a proportion by: \(s.e. (p)={\sqrt {p(1-p)} \over {n}}\)
So we need to get n and p, that’s easy:
FALSE TRUE 49 8584
p<-prop.table(wtd.table(brfss_17$badhealth, brfss_17$educ, weights = brfss_17$mmsawt), margin=2)
t(p) 0 12hsgrad 0.75772036 0.24227964 0Prim 0.60034582 0.39965418 1somehs 0.65504645 0.34495355 3somecol 0.83488335 0.16511665 4colgrad 0.91152544 0.08847456
p<-prop.table(wtd.table(brfss_17$badhealth, brfss_17$male, weights = brfss_17$mmsawt), margin=2)
t(p) 0 1Female 0.7874293 0.2125707 Male 0.8189765 0.1810235
se<-(p*(1-p))/n[2]
stargazer(data.frame(proportion=p, se=sqrt(se)), summary = F, type = "html", digits = 2)| proportion.Var1 | proportion.Var2 | proportion.Freq | se.Var1 | se.Var2 | se.Freq | |
| 1 | 0 | Female | 0.79 | 0 | Female | 0.004 |
| 2 | 1 | Female | 0.21 | 1 | Female | 0.004 |
| 3 | 0 | Male | 0.82 | 0 | Male | 0.004 |
| 4 | 1 | Male | 0.18 | 1 | Male | 0.004 |
Which shows us the errors in the estimates based on the weighted proportions. That’s nice, but since we basically inflated the n to be the population of the US, these standard errors are too small. This is another example of using survey statistical methods, to get the right standard error for a statistic.
Proper survey design analysis
#Now consider the full sample design + weights
cat<-prop.table(svytable(~badhealth+educ, design = des), margin = 2)
knitr::kable(round(100*t(cat), digits = 3))| 0 | 1 | |
|---|---|---|
| 2hsgrad | 75.772 | 24.228 |
| 0Prim | 60.035 | 39.965 |
| 1somehs | 65.505 | 34.495 |
| 3somecol | 83.488 | 16.512 |
| 4colgrad | 91.153 | 8.847 |
Pearson's X^2: Rao & Scott adjustmentdata: svychisq(~badhealth + educ, design = des) F = 25.872, ndf = 3.7069, ddf = 31819.8445, p-value < 0.00000000000000022
| badhealth | educ | Freq | |
| 1 | 0 | 2hsgrad | 0.758 |
| 2 | 1 | 2hsgrad | 0.242 |
| 3 | 0 | 0Prim | 0.600 |
| 4 | 1 | 0Prim | 0.400 |
| 5 | 0 | 1somehs | 0.655 |
| 6 | 1 | 1somehs | 0.345 |
| 7 | 0 | 3somecol | 0.835 |
| 8 | 1 | 3somecol | 0.165 |
| 9 | 0 | 4colgrad | 0.912 |
| 10 | 1 | 4colgrad | 0.088 |
Which gives the same %’s as the weighted table above, but we also want the correct standard errors for our bad health prevalences.
The svyby() function will calculate statistics by groups, in this case we want the % in bad health by each level of education. The %’s can be gotten using the svymean() function, which finds means of variables using survey design:
sv.table<-svyby(formula = ~badhealth, by = ~educ, design = des, FUN = svymean, na.rm=T)
stargazer(sv.table, summary = F, type = "html", digits = 2)| educ | badhealth | se | |
| 2hsgrad | 2hsgrad | 0.24 | 0.02 |
| 0Prim | 0Prim | 0.40 | 0.05 |
| 1somehs | 1somehs | 0.34 | 0.04 |
| 3somecol | 3somecol | 0.17 | 0.01 |
| 4colgrad | 4colgrad | 0.09 | 0.01 |
And we see the same point estimates of our prevalences as in the simple weighted table, but the standard errors have now been adjusted for survey design as well, so they are also correct. You also see they are much larger than the ones we computed above, which assumed random sampling.
Another way
There’s this great R package, tableone that does this stuff very nicely and incorporates survey design too. Here’s an example of using it to generate your bivariate tests like above:
library(tableone)
#not using survey design
t1<-CreateTableOne(vars = c("educ", "marst", "male"), strata = "badhealth", test = T, data = brfss_17)
#t1<-print(t1, format="p")
print(t1,format="p")## Stratified by badhealth
## 0 1 p test
## n 6780 1804
## educ (%) <0.001
## 2hsgrad 20.0 30.9
## 0Prim 3.1 8.7
## 1somehs 4.3 9.9
## 3somecol 25.7 27.2
## 4colgrad 46.9 23.2
## marst (%) <0.001
## married 53.4 41.1
## cohab 3.4 2.5
## divorced 11.9 16.6
## nm 16.1 13.9
## separated 2.0 5.1
## widowed 13.2 20.8
## male = Male (%) 43.0 36.8 <0.001#using survey design
st1<-svyCreateTableOne(vars = c("educ", "marst", "male"), strata = "badhealth", test = T, data = des)
#st1<-print(st1, format="p")
print(st1, format="p")## Stratified by badhealth
## 0 1 p test
## n 12308745.3 3023838.2
## educ (%) <0.001
## 2hsgrad 23.4 30.5
## 0Prim 6.1 16.6
## 1somehs 6.6 14.2
## 3somecol 32.3 26.1
## 4colgrad 31.6 12.6
## marst (%) <0.001
## married 52.9 46.4
## cohab 5.6 3.3
## divorced 9.5 15.0
## nm 24.9 21.0
## separated 2.1 7.0
## widowed 4.9 7.3
## male = Male (%) 49.7 44.7 0.088Regression example
Next we apply this logic to a regression case. First we fit the OLS model for our BMI outcome using education and age as predictors:
Next we incorporate case weights
Now we will incorporate design effects as well:
Now I make a table to show the results of the three models:
stargazer(fit1, fit2, fit3, style="demography", type="html",
column.labels = c("OLS", "Weights Only", "Survey"),
title = "Regression models for BMI using survey data - BRFSS 2016",
covariate.labels=c("PrimarySchool", "SomeHS", "SomeColl", "CollGrad", "Age 24-39","Age 39-59" ,"Age 59-79", "Age 80+"),
keep.stat="n", model.names=F, align=T, ci=T)| bmi | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OLS | Weights Only | Survey | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Model 1 | Model 2 | Model 3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PrimarySchool | 0.134 | -0.581* | -0.581 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (-0.642, 0.911) | (-1.143, -0.020) | (-1.841, 0.678) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SomeHS | -0.023 | -0.743** | -0.743 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (-0.699, 0.652) | (-1.302, -0.183) | (-2.093, 0.608) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SomeColl | -0.477* | -1.305*** | -1.305** | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (-0.880, -0.074) | (-1.668, -0.943) | (-2.146, -0.465) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| CollGrad | -1.997*** | -2.513*** | -2.513*** | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (-2.365, -1.628) | (-2.889, -2.137) | (-3.281, -1.745) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Age 24-39 | 2.930*** | 3.215*** | 3.215*** | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (2.251, 3.609) | (2.765, 3.666) | (2.341, 4.089) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Age 39-59 | 4.376*** | 4.773*** | 4.773*** | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (3.731, 5.020) | (4.335, 5.211) | (3.897, 5.649) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Age 59-79 | 3.467*** | 4.011*** | 4.011*** | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (2.837, 4.096) | (3.537, 4.486) | (3.051, 4.971) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Age 80+ | 0.792* | 0.815 | 0.815 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (0.060, 1.524) | (-0.054, 1.684) | (-0.496, 2.126) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Constant | 26.082*** | 26.221*** | 26.221*** | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (25.462, 26.702) | (25.804, 26.638) | (25.382, 27.060) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| N | 7,891 | 7,891 | 7,891 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
</sup>p < .05; </sup>p < .01; </strong></em>p < .001
</td>
</tr>
</table>
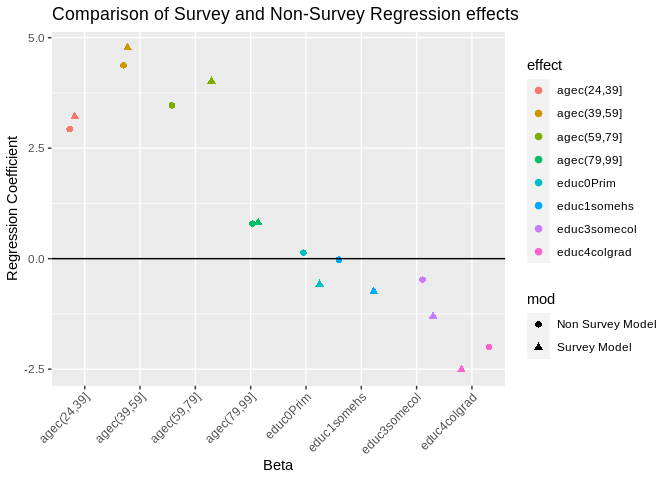
Notice, the results for the education levels are much less significant than the were with either of the other two analysis. This is because those models had standard errors for the parameters that were too small. You see all the standard errors are larger and the T statistics are smaller. Which shows the same \(\beta\)’s between the survey design model and the weighted model but the standard errors are larger in the survey model, so the test statistics are more conservative (smaller t statistics). While in this simple model, our overall interpretation of the effects do not change (positive effects of education, negative effects of age), it is entirely possible that they could once we include our survey design effects. It may be informative to plot the results of the models to see how different the coefficients are from one another:
Which shows us that the betas are similar but have some differences between the two models. </div>Creating Survey estimates for placesOne of the coolest ways to use the BRFSS is to calculate estimates for places, and by demographic characteristics withing places. Again, we use
Using srvyrThere’s a new package called Replicate WeightsIf your dataset comes with replicate weights, you have to specify the survey design slightly differently. Here is an example using the IPUMS CPS data. For this data, you can get information here, but you must consult your specific data source for the appropriate information for your data. So we see the replicate weights are in columns 8 through 167 in the data | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||